
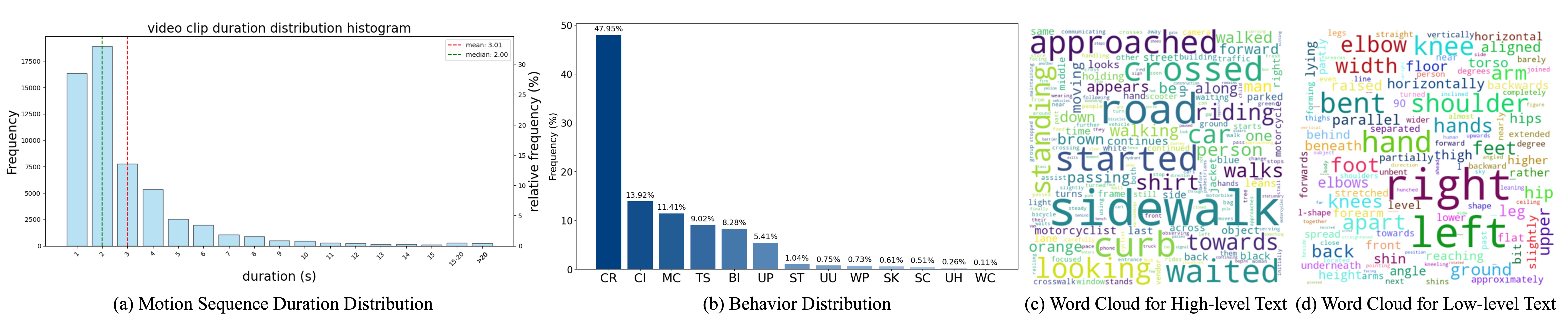
The statistics of the MMHU dataset.
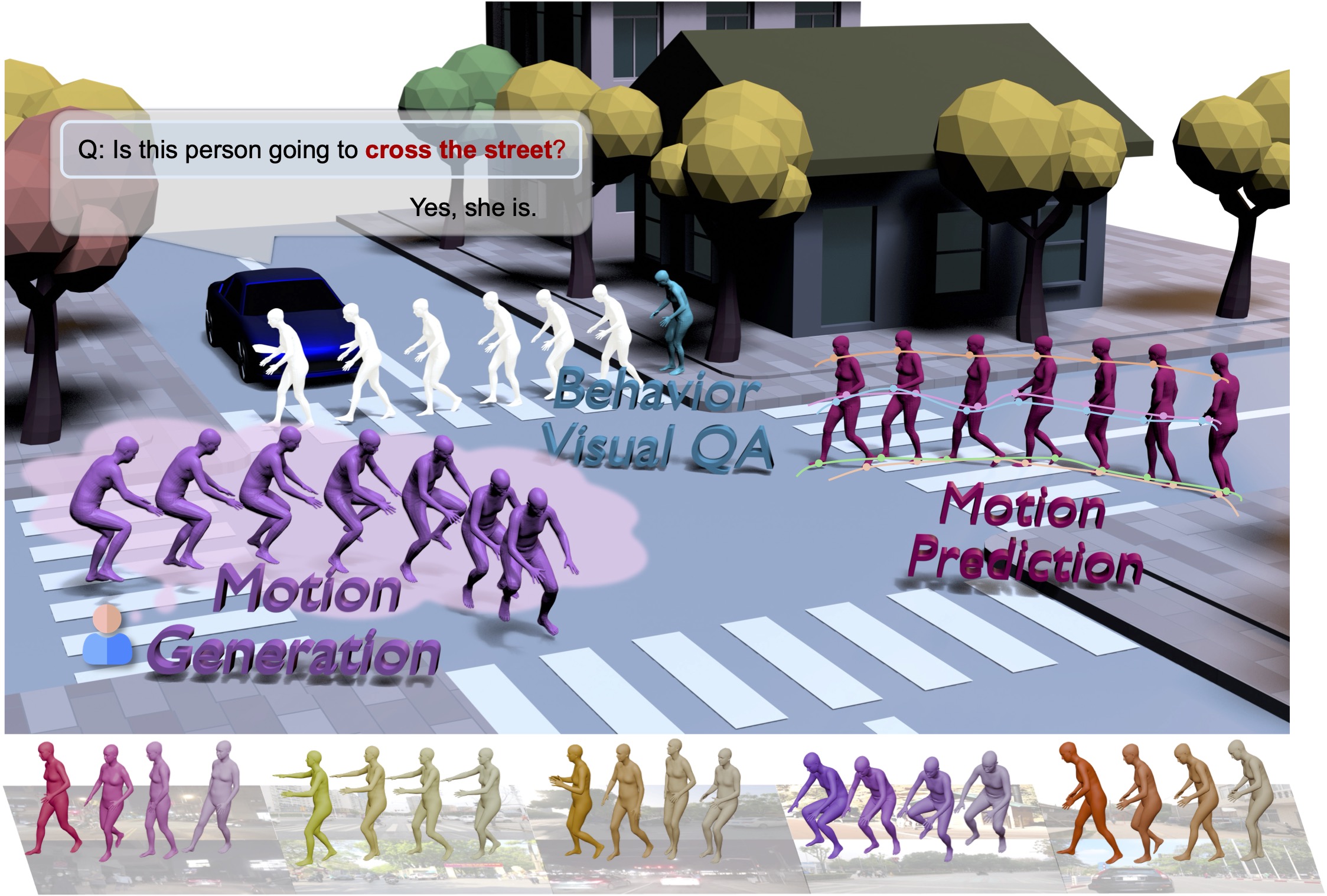
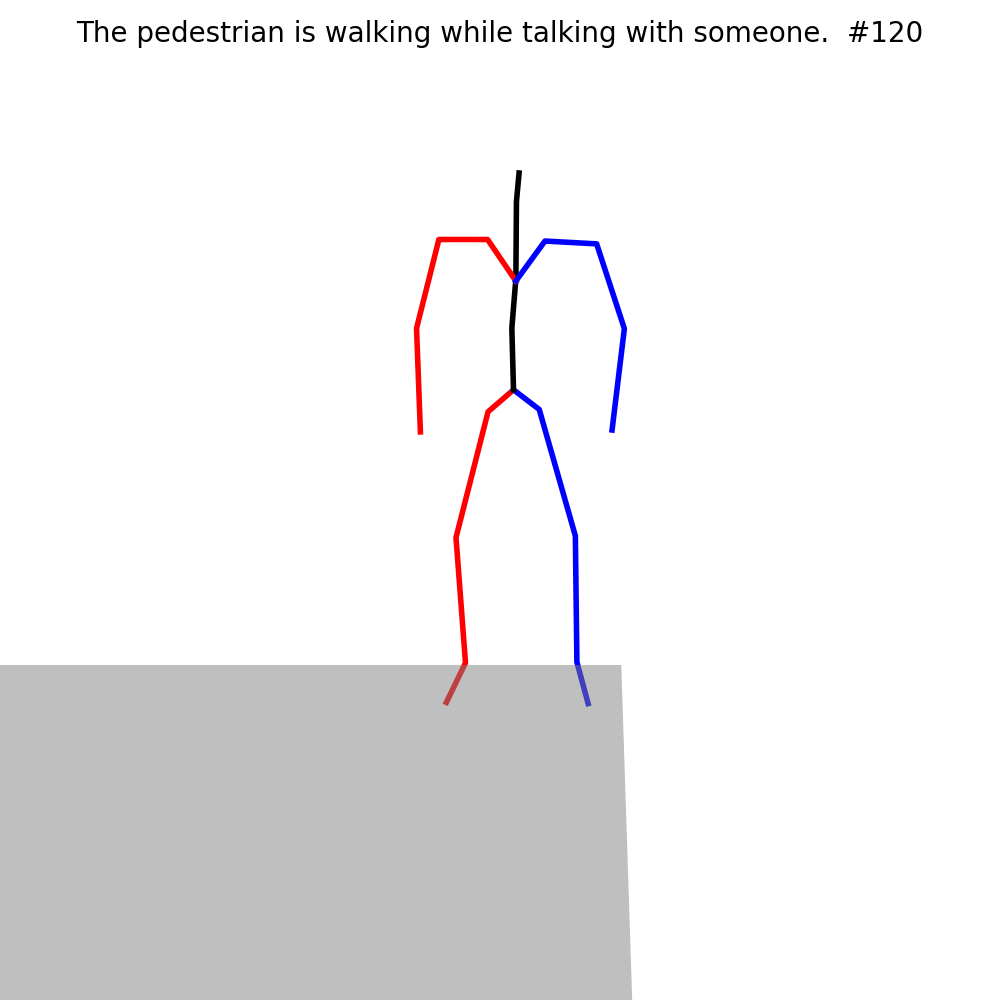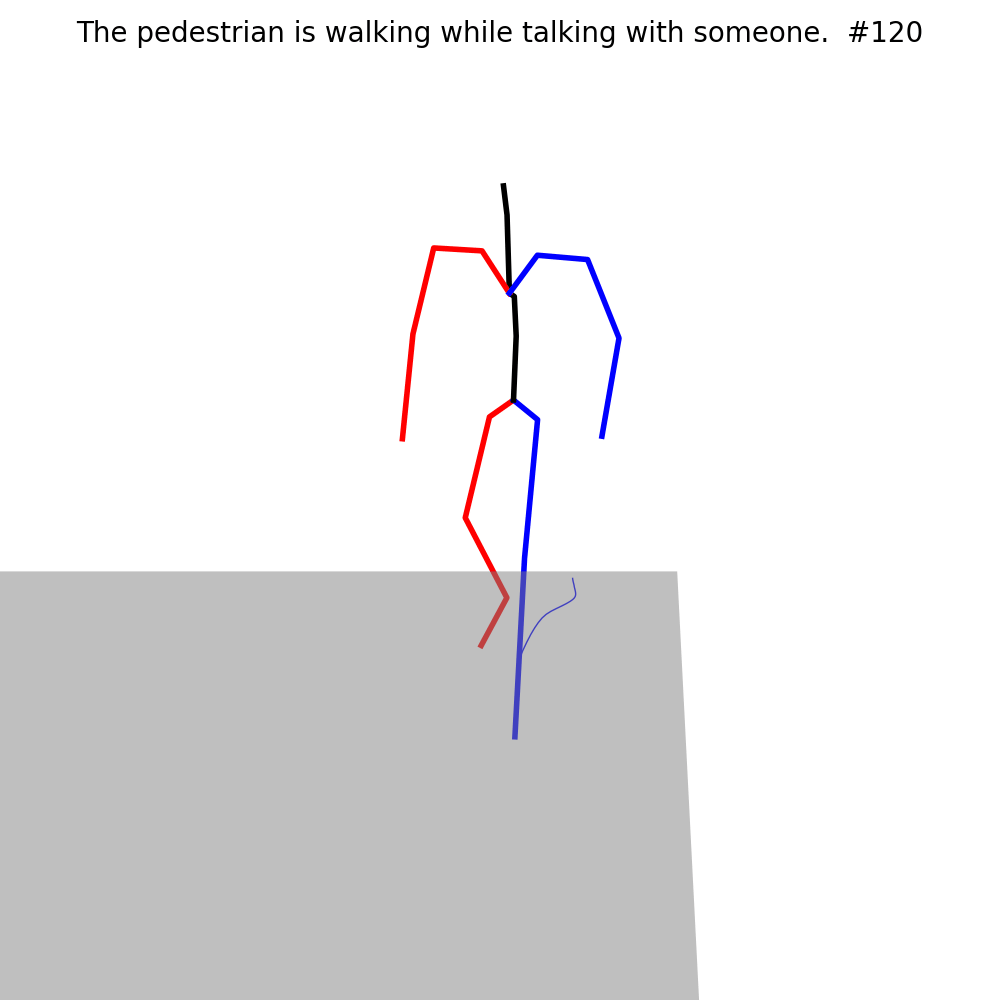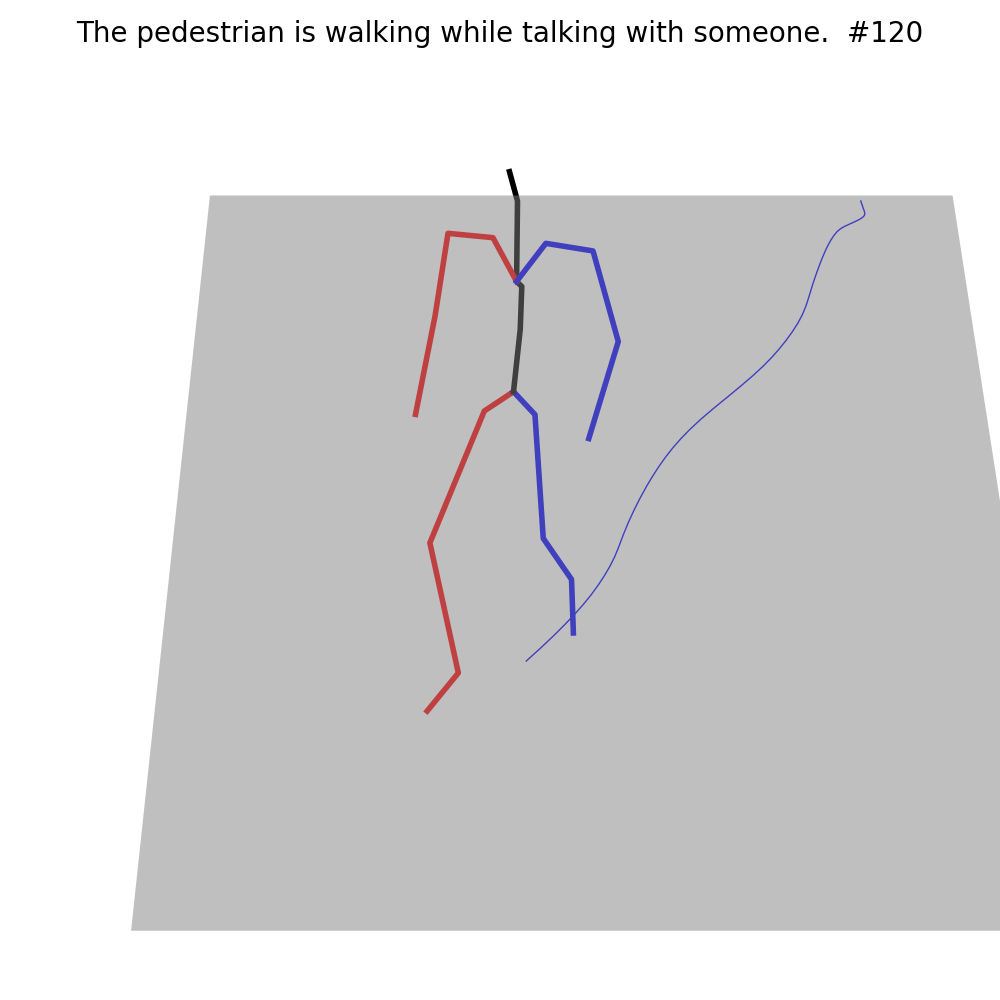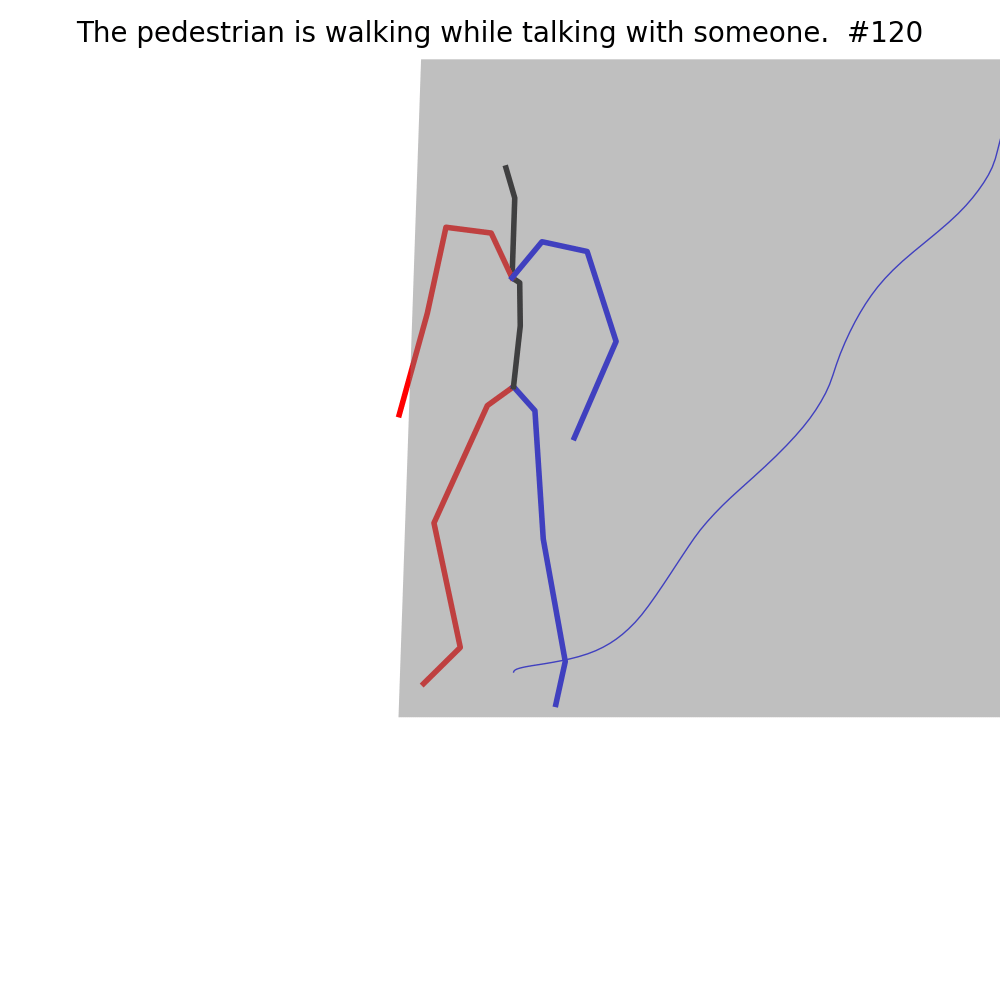
Some examples of MMHU: each sample contains the motion sequence rendered on the original image, the behavior tags, and the text descriptions.
We collect data from three sources: the Waymo dataset, the YouTube videos, and the self-collected or paid driving videos. We designed a labeling pipeline to obtain high-quality data annotation with minimal human effort.

The current Motion Generation approaches are not capable of generating human motion in the street context (Left of each example). With fine-tuning on MMHU, they can properly generate such human motions (Right of each example).
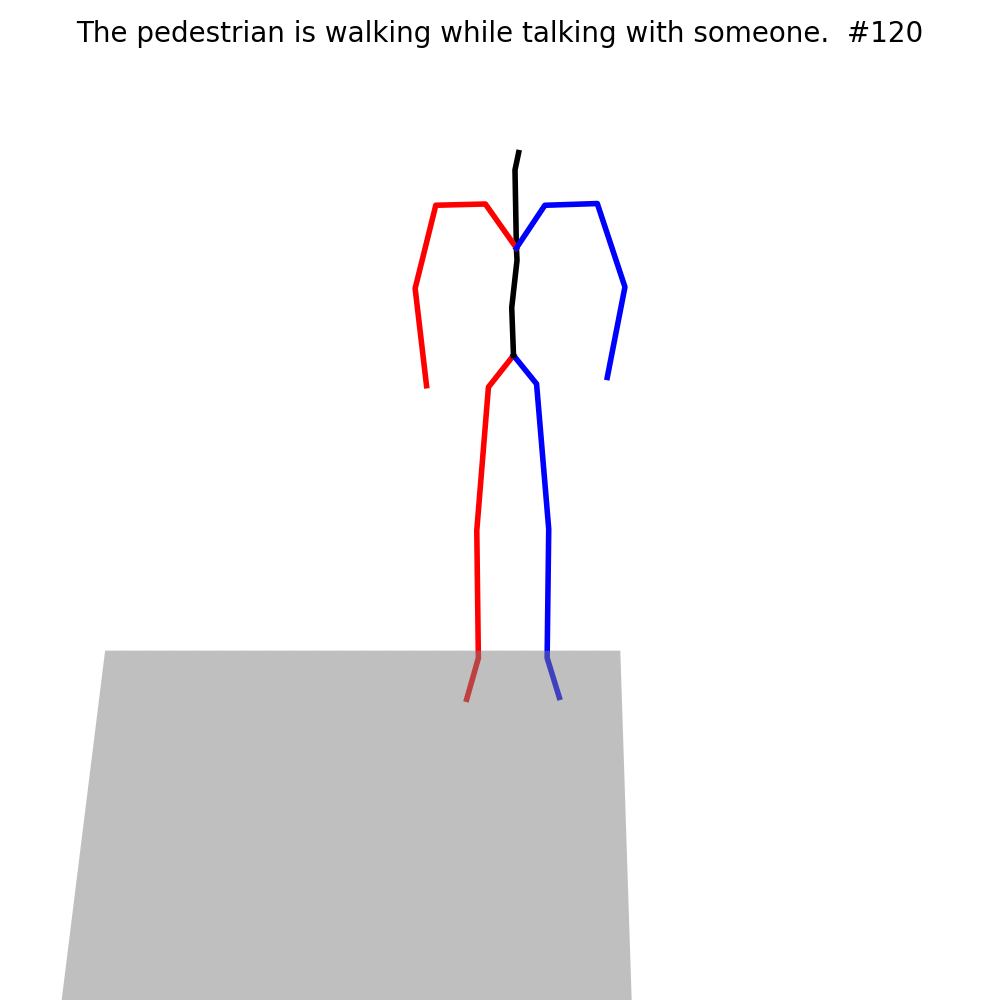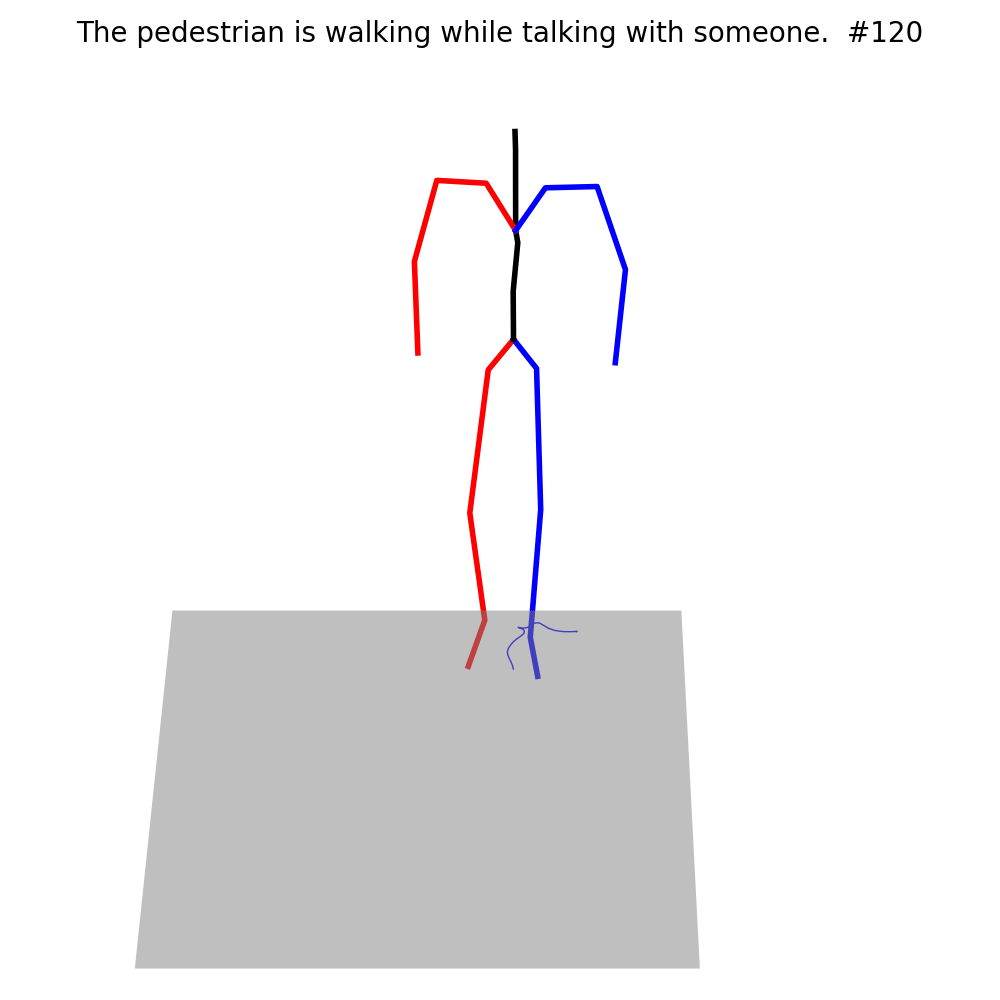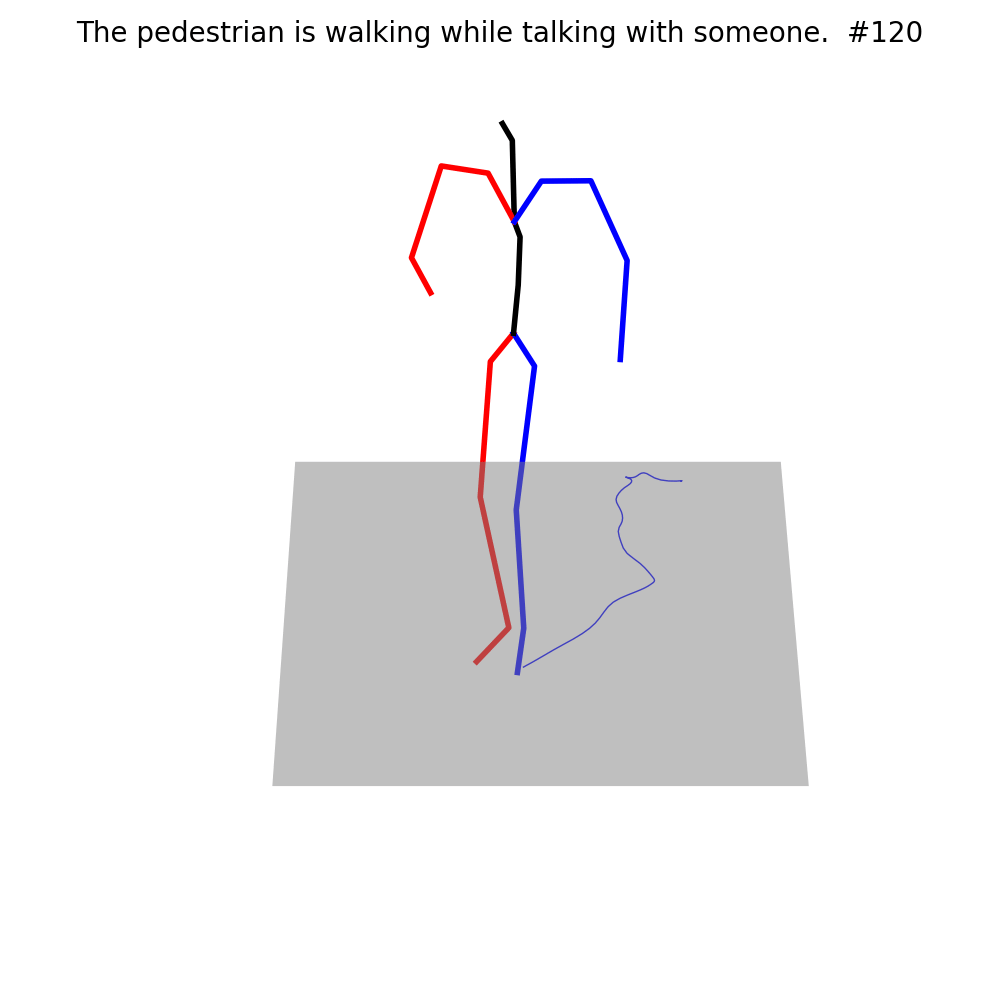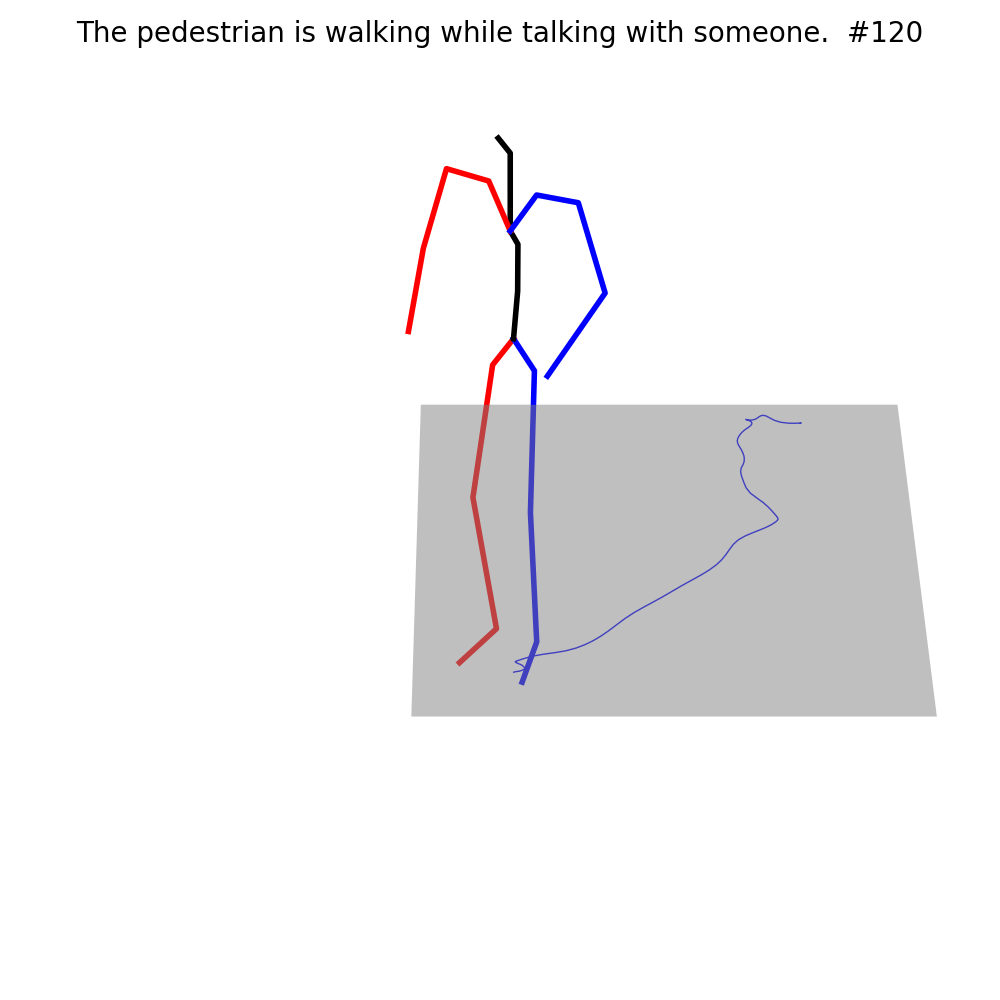
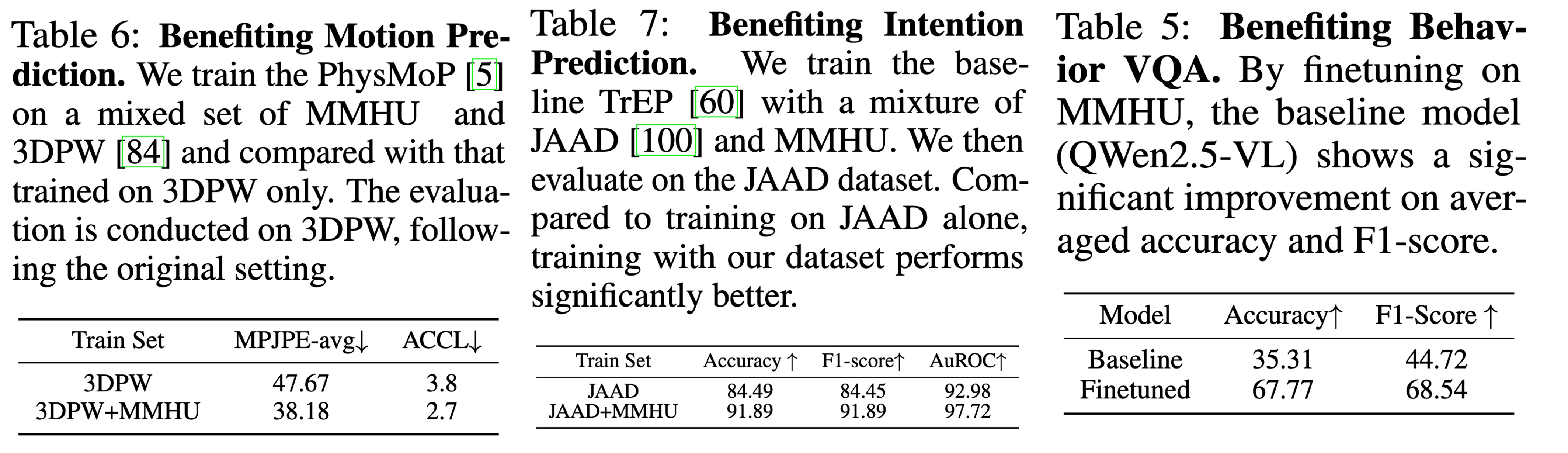
Fine-tuning on MMHU also improves the performance of the baseline models on
Motion Prediction,
Intention Prediction, and Behavior VQA.
@misc{li2025mmhumassivescalemultimodalbenchmark,
title={MMHU: A Massive-Scale Multimodal Benchmark for Human Behavior Understanding},
author={Renjie Li and Ruijie Ye and Mingyang Wu and Hao Frank Yang and Zhiwen Fan and Hezhen Hu and Zhengzhong Tu},
year={2025},
eprint={2507.12463},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.12463},
}